Intro to Computational Semiotics Series
Jan 2026
My friend Brandon from Calcifer Computing (@calco_io on X) is giving an Introduction to Computational Semiotics lecture series at Johns Hopkins this Intersession, and I’m learning along with his students as I watch the lectures he’s shared online.
I’m interested in computational semiotics because we are in the middle of a major shift in how we use language at scale, and we have access to more information about human cultural circuitry than ever.
If we want to be able to reason about it, then we have to study how meaning spreads and shifts over time.
What is Computational Semiotics?
A lot of people I’ve talked to about this had no idea that this is even a field. So even though Brandon’s slide which defines the field occurs late in the lecture, I’ll include it up front:

Brandon spends most of the class not talking about computational semiotics directly, but rather giving a very brief history of the relevant philosophies that contextualize the field — Plato, Diogenes, Frege, Russell, Wittgenstein, De Saussure, Peirce, Rorty, Deleuze and Guattari.
I’ll spare all the details, but what I loved was how he selected and presented the exemplars from each of these thinkers, and connected them to contemporary machine learning/LLM topics.
Note: if you feel lost as you read this article, I recommend you jump to the lecture itself, because Brandon does a great job packing a lot into it in an accessible way.
ML connections
He compares Plato’s Allegory of the Cave to the concept of projection in linear algebra. Just as Plato’s Forms cast their shadow as the particulars on the cave wall, projection computes the “shadow” a vector casts on a lower-dimensional surface.

When discussing Wittgenstein’s Language Games (how the meaning of words and sentences is determined by their use in specific contexts or activities), he uses the example of BERT training with Cloze games. Trainers mask words in a sentence, get the model to guess the words, and then the model learns through this process.

He also brings in Chain of Thought Steganography, which is relevant to AI Alignment Research. This happens when a model is essentially able to encode meaning in the words in its Chain of Thought to make it appear as if it’s not thinking about something it has been penalized for in the past, even though it is.
Including these examples throughout helped me stay grounded in how this is relevant to my interests.
Wait but why?

Why do we look at “spread and distortion?”
Why do we need signs to be “stable over context?”
Spread: Particular people are all using the same word to describe a reference. Studying them can tell us something about the structure of the communication. Brandon likens it to contact tracing in epidemiology.
Distortion: Looking not just at who is saying a word, but what words they’re saying next to it. How are the contexts changing? Is the distortion productive in some way?
Stability over context: Well, we can only research sufficiently stable signs.
What is the “plan of attack?”
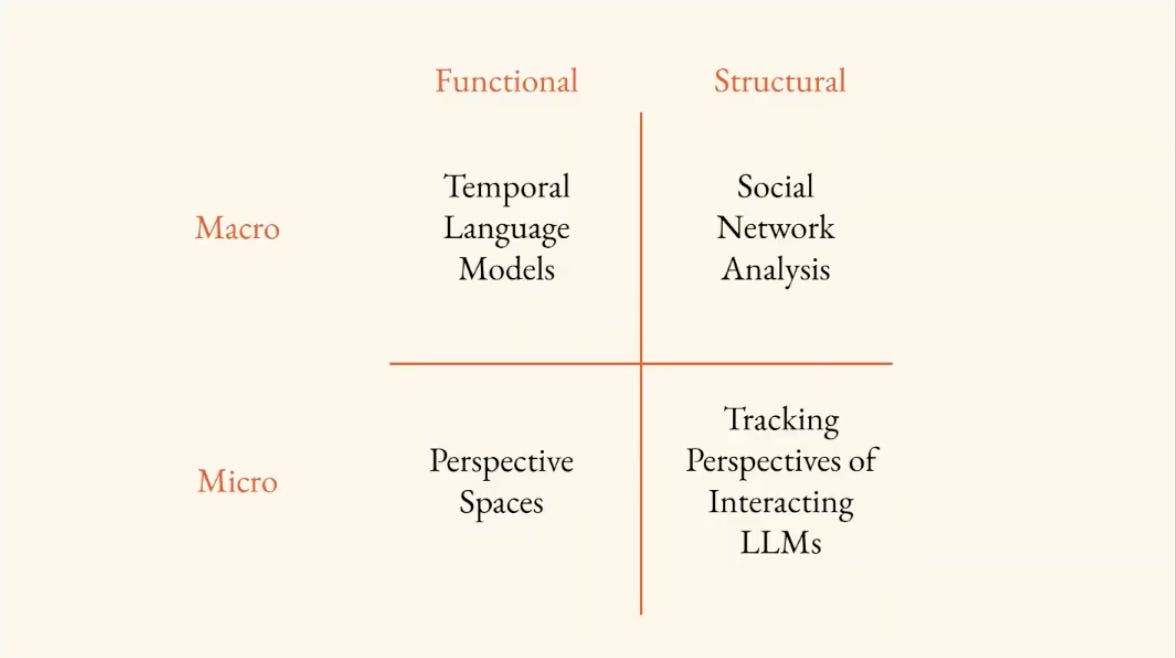
Brandon breaks down the research methods in this field into two axes which form a matrix: Functional/Structural, and Macro/Micro.
-
Functional focuses on the language process itself.
-
Structural focuses on the terrain through which language flows.
-
Macro focuses on language produced by ensembles.
-
Micro focuses on language produced by discrete individuals.
You can see the matrix with some tools for studying language here:
Why study Computational Semiotics at all?
“Language is somehow like the API through which all the rest of the change in the world flows.”
Brandon draws the analogy:
People:Language::Neurons:Action Potential.
People use language to drive action just like neurons use action potentials to move the body. Currently, we’re in a situation where we have generative AI models enabling mass modification of our language, which potentially gives others the leverage to mass-modify our actions.
We learn about computational semiotics so we can reason about how we make meaning and build/shape our worlds through language.
I’ll be spending some time with these concepts throughout Inkuary and during long train rides as I travel. I plan to continue sharing my quick thoughts or research into CompSemi here and there, both via this substack and X.
There was much more covered that I couldn’t include in this overview, so again, I recommend you also check the lecture out yourself.
If you would like to learn along with me, let me know via comments or twitter/X DM, and I’ll make sure you get Brandon’s lecture links as they’re published.
So Long,
Marianne